

Eine Eingabeaufforderung ist eine Nachricht, die dem Kontakt![]() Die Person, die mit einem Agenten, IVR oder Bot in Ihrem Contact Center interagiert. während einer Interaktion vorgespielt wird. Aufforderungen können den Kontakt zur Eingabe von Informationen auffordern oder einfach Informationen vermitteln, ohne eine Eingabe zu verlangen. Sie können von automatischen Vermittlungsstellen, interaktiven Sprachantwortsystemen (IVR
Die Person, die mit einem Agenten, IVR oder Bot in Ihrem Contact Center interagiert. während einer Interaktion vorgespielt wird. Aufforderungen können den Kontakt zur Eingabe von Informationen auffordern oder einfach Informationen vermitteln, ohne eine Eingabe zu verlangen. Sie können von automatischen Vermittlungsstellen, interaktiven Sprachantwortsystemen (IVR![]() Interactive Voice Response (Interaktive Sprachausgabe). Automatisiertes Telefonmenü, mit dem Anrufer durch Sprachbefehle oder Tasteneingaben interagieren, um Informationen zu erhalten, einen eingehenden Sprachanruf zu routen oder beides.) und anderen Sprachverarbeitungstools abgespielt werden. Wenn Sie ein Unternehmen anrufen und ein Menü mit der Option „Drücken Sie 1 für den Vertrieb oder 2 für den Support“ hören, hören Sie eine Aufforderung, die von einem IVR abgespielt wird.
Interactive Voice Response (Interaktive Sprachausgabe). Automatisiertes Telefonmenü, mit dem Anrufer durch Sprachbefehle oder Tasteneingaben interagieren, um Informationen zu erhalten, einen eingehenden Sprachanruf zu routen oder beides.) und anderen Sprachverarbeitungstools abgespielt werden. Wenn Sie ein Unternehmen anrufen und ein Menü mit der Option „Drücken Sie 1 für den Vertrieb oder 2 für den Support“ hören, hören Sie eine Aufforderung, die von einem IVR abgespielt wird.
Bei den Eingabeaufforderungen kann es sich um vorab aufgezeichnete Audiodateien handeln oder sie können von einem Text-to-Speech-Dienst (TTS) gesprochen werden. Sie können auch Eingabeaufforderungen erstellen, die aufgezeichnetes Audio und TTS kombinieren.
Eingabeaufforderungen sind in Studio-Skripten integriert. Zur Verwendung von Aufforderungen benötigen Sie eine Aktion, die Aufforderungen unterstützt. Dazu zählen Aktionen wie Play oder Whisper sowie ASR![]() Automatic Speech Recognition (automatische Spracherkennung). Ermöglicht es Kontakten, auf Aufforderungen durch Sprechen zu reagieren, Telefontasten zu drücken oder beides.-Aktionen wie ASR oder ASRMENU.
Automatic Speech Recognition (automatische Spracherkennung). Ermöglicht es Kontakten, auf Aufforderungen durch Sprechen zu reagieren, Telefontasten zu drücken oder beides.-Aktionen wie ASR oder ASRMENU.
Möglichkeiten zum Erstellen von Aufforderungen
In CXone Mpower kann es sich bei Aufforderungen um bereits aufgezeichnete Audiodateien handeln oder um Text, der von einem Text-to-Speech-Dienst (TTS![]() Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts.) vorgelesen wird.
Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts.) vorgelesen wird.
So erstellen Sie vorab aufgezeichnete Audiodateien zur Verwendung in Aufforderungen:
- Verwenden Sie die Aufnahmefunktion, die in den Sequenzeditor in Studiointegriert ist.
- Verwenden Sie die Aufzeichnungsanwendung eines Drittanbieters. Anschließend können Sie die Dateien mit Desktop Studio oder Studio
So erstellen Sie Text-to-Speech-Ansagen, die von einem TTS-Dienst vorgelesen werden:
- Verwenden Sie den Sequenz-Editor. Sie können über jede Aktion, die Aufforderungen unterstützt, auf dieses Tool zugreifen. Der Sequenz-Editor bietet eine Benutzeroberfläche, mit der Sie die Aufforderung erstellen können
- Erstellen Sie die Eingabeaufforderungssequenz direkt in der Sequence-Eigenschaft einer beliebigen Aktion, die Eingabeaufforderungen unterstützt.
Reihenfolgen
Eine Aufforderung besteht aus einem oder mehreren Segmenten, die Sequenzen (oder auch Reihenfolgen) genannt werden. Sequenzen definieren die Teile einer Eingabeaufforderung. Eine Aufforderung kann aus einer einzelnen Sequenz bestehen oder mehrere Sequenzen enthalten. Mehrere Sequenzen sind in den folgenden Fällen erforderlich:
- Der Text der Aufforderung ist länger als 300 Zeichen.
- Die Aufforderung enthält Datum/Uhrzeit-Angaben, Geldbeträge, Zahlen oder Text, der buchstabiert werden soll. Für diese speziellen Inhalte sind eigene Sequenzen erforderlich. Die speziellen Sequenzen enthalten Kennungen, damit der TTS-Dienst weiß, wie sie korrekt ausgesprochen werden.
- Die Aufforderung enthält eine Kombination aus TTS und vorab aufgezeichneten Audiodateien.
- Sie möchten die Eingabeaufforderung aufteilen, um sie im Sequenzeditor oder im Feld Sequence leichter lesbar zu machen.
Sie können Sequenzen im Sequenzeditor oder direkt im Sequence-Eigenschaftsfeld von Aktionen hinzufügen, die Eingabeaufforderungen unterstützen.
Sequenz-Editor
Mit dem Sequenz-Editor können Sie Audio- und TTS![]() Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts.-Aufforderungen erstellen, die das Skript für Kunden abspielt.
Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts.-Aufforderungen erstellen, die das Skript für Kunden abspielt.
![]() Automatic Speech Recognition (automatische Spracherkennung). Ermöglicht es Kontakten, auf Aufforderungen durch Sprechen zu reagieren, Telefontasten zu drücken oder beides.-Aktionen wie Asrmenu.
Automatic Speech Recognition (automatische Spracherkennung). Ermöglicht es Kontakten, auf Aufforderungen durch Sprechen zu reagieren, Telefontasten zu drücken oder beides.-Aktionen wie Asrmenu.
Sie können den Sequenz-Editor für folgende Zwecke verwenden:
- Erstellen einer TTS-Aufforderung.
- Audioansagen aufzeichnen.
- Wählen Sie eine vorab aufgezeichnete Audiodatei aus, die die Aktion abspielen soll. Sie können Dateien mit dem Sequenz-Editor aufzeichnen oder Sie können sie in einer anderen Anwendung erstellen und dann in CXone Mpower hochladen.
Formatierung für Aufforderungen in der Eigenschaft "Reihenfolge"
Sequence ist eine Eigenschaft in Aktionen, die Aufforderungen unterstützen, wie Menu oder Play. Sie enthält die Sequenzdefinition der Aufforderung. Das Skript verwendet die Sequenzdefinition, um die Aufforderung für den Kontakt abzuspielen.
Sequenzen müssen korrekt formatiert werden. Anhand der Formatierung kann das Skript erkennen, welche Informationen in der Reihenfolge enthalten sind. Wenn Sie die Aufforderung mit dem Sequenz-Editor erstellen, ist der Inhalt der Sequence-Eigenschaft bereits korrekt formatiert. Wenn Sie die Aufforderung direkt in eine Sequence-Eigenschaft eingeben, müssen Sie die erforderliche Formatierung manuell anwenden.
Jede Sequenz muss in doppelte Anführungszeichen eingeschlossen werden. Einige Sequenzen müssen auch ein Sonderzeichen enthalten, das dem Skript mitteilt, wie der Text in der Sequenz gelesen werden soll. In den folgenden Abschnitten finden Sie genauere Informationen über die Formatierung von Sequenzen.
Dateinamen der Audio-Aufforderung
Bei voraufgezeichneten Audioansagen enthält die Eigenschaft Sequence den Namen der abzuspielenden Audiodatei. Formatieren Sie diese, indem Sie den Namen in doppelte Anführungszeichen setzen. Zum Beispiel: "Begrüßung.wav".
Wenn Sie den Dateinamen nicht in doppelte Anführungszeichen setzen, wird er vom Skript möglicherweise nicht als Dateiname erkannt. Wenn der Dateiname ein Leerzeichen enthält, kann sich die Aufforderung auf unerwartete Weise verhalten.
Wenn die Audiodatei für eine Aufforderung zum Beispiel primäre Begrüßung.wav heißt, interpretiert das Skript primäre als Text, der vom TTS![]() Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts.-Dienst gelesen wird, und sucht nach einer Audiodatei mit dem Namen Begrüßung.wav. Sollte Begrüßung.wav vorhanden sein, wird diese Datei wiedergegeben. Sollte Begrüßung.wav nicht vorhanden sein, führt dies zu einem Fehler. Sie können dies vermeiden, indem Sie den Dateinamen in doppelte Anführungszeichen einschließen und den Empfehlungen für Dateinamen folgen.
Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts.-Dienst gelesen wird, und sucht nach einer Audiodatei mit dem Namen Begrüßung.wav. Sollte Begrüßung.wav vorhanden sein, wird diese Datei wiedergegeben. Sollte Begrüßung.wav nicht vorhanden sein, führt dies zu einem Fehler. Sie können dies vermeiden, indem Sie den Dateinamen in doppelte Anführungszeichen einschließen und den Empfehlungen für Dateinamen folgen.
Text für TTS-Eingabeaufforderungen formatieren
Für Text-to-Speech-Aufforderungen (TTS![]() Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts.) enthält die Eigenschaft Sequence den Text, den der TTS-Dienst sprechen soll. Befolgen Sie diese Richtlinien beim Formatieren Ihrer Aufforderung:
Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts.) enthält die Eigenschaft Sequence den Text, den der TTS-Dienst sprechen soll. Befolgen Sie diese Richtlinien beim Formatieren Ihrer Aufforderung:
-
Schließen Sie den Text in doppelte Anführungszeichen ein.
"%Drücken Sie 1 für Kontoinformationen. Drücken Sie 2 für den Bestellstatus. Drücken Sie 3 für die Rechnungsstellung. Oder bleiben Sie in der Leitung, um mit einem Agenten zu sprechen."
-
Verwenden Sie ein String-Referenzzeichen, um den Texttyp zu identifizieren, den jede Reihenfolge enthält. Es gibt String-Referenzzeichen zum Identifizieren von gewöhnlichem Text oder Text, der ausbuchstabiert werden soll. Es gibt außerdem Zeichen, die Daten, Zahlen, Geldbeträge und Zeit identifizieren. Einzelheiten finden Sie in der Tabelle im Abschnitt über die Verwendung von Zahlen, Geldbeträgen, Uhrzeitangaben und so weiter in Aufforderungen. Beispiele sind in der Tabelle enthalten. Wenn kein String-Referenzzeichen enthalten ist, liest der TTS-Dienst den Text mit der standardmäßigen Aussprache.
-
Wenn Ihre Aufforderung Text enthält, für den mehrere String-Referenzzeichen erforderlich sind, muss der Text, der von verschiedenen Referenzzeichen definiert wird, jeweils in einer separaten Sequenz enthalten sein. Jede Sequenz muss in doppelte Anführungszeichen eingeschlossen werden. Die Sequence-Eigenschaft kann viele separate Sequenzen enthalten. Zum Beispiel:
"%Vielen Dank für Ihren Anruf. Leider sind wir zurzeit geschlossen. Unsere Geschäftszeiten sind Montag bis Freitag" "!8:00 Uhr" "%bis" "!5:00 Uhr" "%. Bitte rufen Sie zurück."
-
Sie können Variablen in eine Reihenfolge aufnehmen. Schließen Sie die Variablen in geschweifte Klammern ({ }) ein. Wenn die Variable einen Wert enthält, der ein anderes String-Referenzzeichen erfordert, verwenden Sie doppelte Anführungszeichen, um jede Reihenfolge entsprechend zu definieren. Zum Beispiel:
"%Mit Stand" "@{today}" "%beträgt Ihr Kontostand" "${accountBal}."
- Sie können Audiodateien und TTS-Text in einer Aufforderung kombinieren. Beispielsweise können Sie eine leere Audiodatei verwenden, um eine längere Pause zwischen Sätzen hinzuzufügen. In diesem Fall müssen Sie die Datei bearbeiten, sodass sie genau die Länge der gewünschten Pause hat.
-
In Desktop Studio können Sequenzen der Eigenschaft Sequence horizontal hinzugefügt werden, wie im vorigen Beispiel in diesem Abschnitt gezeigt, oder vertikal, wie im folgenden Beispiel. Die Ausrichtung wirkt sich nicht darauf aus, wie die Aufforderung gelesen wird. Um eine Sequenz vertikal hinzuzufügen, klicken Sie auf das Auslassungszeichen
 neben der Eigenschaft Sequence, um ein kleines Editor-Fenster zu öffnen.
neben der Eigenschaft Sequence, um ein kleines Editor-Fenster zu öffnen."%As of"
"@{today}"
"%your account balance is"
"${accountBal}." -
Sie können den Sequenzeditor jederzeit öffnen und weiter an Ihrer TTS-Eingabeaufforderungarbeiten.
Zahlen, Geld, Daten, Zeit und Buchstaben in Aufforderungen
Die Text-to-Speech-Funktion liest Ihren Text Wort für Wort. Situationen, in denen der Text auf verschiedene Weisen gelesen werden kann, werden nicht erkannt. Wenn Sie beispielsweise das Datum 31.01.2022 eingeben, soll es als "31. Januar 2022" gelesen werden, nicht als "drei eins Punkt null eins Punkt zweitausendzweiundzwanzig".
Studio verwendet bestimmte Formatierungen, um Text zu identifizieren, den der TTS-Dienst auf eine bestimmte Weise lesen soll. Die Formatierung besteht aus einem String-Referenzzeichen, das am Anfang einer jeden Sequenz![]() Ein Segment einer Audioaufforderung, die für den Kontakt abgespielt wird. hinzugefügt wird. Es gibt ein spezifisches Zeichen für jeden Inhaltstyp, wie Zahlen oder Datumsangaben. Wenn 31.01.2022 beispielsweise als "31. Januar 2022" gelesen werden soll, stellen Sie dem Text das @-Symbol voran und schließen Sie den ganzen Text in doppelte Anführungszeichen ein: "@31.01.2022".
Ein Segment einer Audioaufforderung, die für den Kontakt abgespielt wird. hinzugefügt wird. Es gibt ein spezifisches Zeichen für jeden Inhaltstyp, wie Zahlen oder Datumsangaben. Wenn 31.01.2022 beispielsweise als "31. Januar 2022" gelesen werden soll, stellen Sie dem Text das @-Symbol voran und schließen Sie den ganzen Text in doppelte Anführungszeichen ein: "@31.01.2022".
In der folgenden Tabelle werden die Formate und String-Referenzzeichen aufgeführt, die in Studio unterstützt werden. Sie sehen auch Beispiele dafür, wie die einzelnen Zeichenfolgen vom TTS-Dienst gelesen werden. Verwenden Sie diese Formatierung, wenn Sie Aufforderungen direkt zur Sequence-Eigenschaft oder zum Feld
| Sequenztyp | Details zur |
|---|---|
| Audiodatei (WAV) |
String-Referenzzeichen: N/A Unterstütztes Format: "filename.wav" Beispiel: "greeting5.wav" |
| Datum wiedergeben |
Unterstützte Formate: Hinweis: Die Datumsformate unterscheiden sich je nach Sprache und Land. Verwenden Sie ein Format, das Ihre Kontakte erkennen und verstehen. |
| Buchstaben |
Beispiel: Sie können Text auch buchstabieren lassen, indem Sie die Tags <spell> </spell> in einer Sequenz für "Ich habe Ihren Namen als <spell>{Name}</spell>. Wenn dies korrekt ist, drücken Sie die 1, andernfalls die 2" |
|
Geldbetrag wiedergeben |
Beispiel: |
| Zahlen wiedergeben |
Beispiel: |
| Zeit wiedergeben |
hh:mm hh:mm:ss Beispiele, wie diese gelesen werden: |
| Text- |
Beispiel: |
| Variablen |
Wenn Sie eine Variable in eine Aufforderung aufnehmen wollen, müssen Sie sie entsprechend formatieren. String-Referenzzeichen: Verwenden Sie diejenige, die der Art der Information entspricht, die die Variable enthält. Wenn Sie eine Variable in eine Sequenz einbeziehen, die weitere Zeichen enthält, benötigen Sie nur ein String-Referenzzeichen am Anfang der Sequenz. Wenn die Variable und die anderen Zeichen andere Arten von Informationen darstellen, zum Beispiel Geldbetrag und Text, erstellen Sie getrennte Sequenzen. Zum Beispiel: "%Ich habe Ihren Namen als {firstName} {lastName}. Ist dies korrekt?" "%Ihr Kontostand lautet:" Unterstütztes Format: In doppelte Anführungszeichen einschließen und geschweifte Klammern einbeziehen |
Variablen in Aufforderungen
Sie können Variablen in Eingabeaufforderungen verwenden. Vergewissern Sie sich, dass das Skript so konzipiert ist, dass es die Informationen, mit denen Sie die Variable füllen wollen, weitergibt. Wenn Sie ein Datum, eine Uhrzeit, eine Zahl oder einen Text übergeben, der buchstabiert werden soll (z. B. um die Schreibweise eines Namens zu überprüfen), muss er so formatiert werden, dass der TTS-Dienst![]() Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts. ihn richtig liest:
Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts. ihn richtig liest:
Sie können Variablen einschließen, unabhängig von der Methode, die Sie zum Erstellen der Aufforderung verwenden:
-
Wenn Sie den Sequenz-Editor verwenden, klicken Sie auf die Schaltfläche für den Informationstyp, den die Variable enthält, wie Zahlen wiedergeben oder Datum wiedergeben. Fügen Sie die Variable dem Feld Sequence Value hinzu. Die Variable kann noch weiteren Text enthalten, sofern es sich um denselben Informationstyp handelt.
- Wenn Sie die Eigenschaft Sequence einer -Aktion verwenden, die Aufforderungen unterstützt, erstellen Sie eine Sequenz mit einer Variablen in dem Format, das in der Tabelle im Abschnitt Formatierung von Zahlen, Geldbeträgen, Datum, Uhrzeit und Buchstaben beschrieben wird. Zum Beispiel: "@{thisDate}".
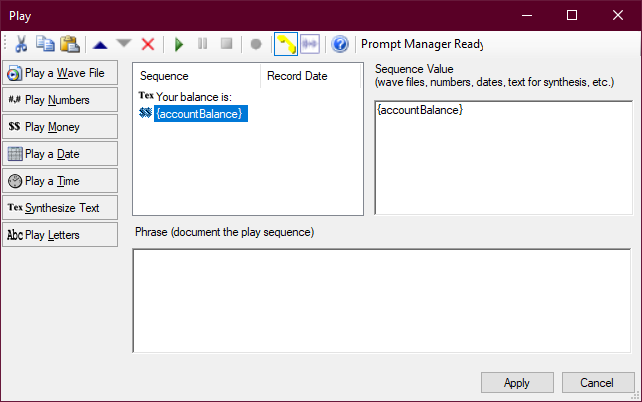
Beowulf, der Studio-Skriptentwickler bei Classics, Inc., verwendet Variablen, um eine sprachspezifische Version einer vorab aufgenommenen Audioansage auszuwählen, den Pfad zur Audiodatei anzugeben und kontaktspezifische Daten bereitzustellen. Er legt die folgenden Variablen in einer Snippet-Aktion fest:
ASSIGN env = "PROD" ASSIGN lang = "ENG" ASSIGN promptPath = "Prompts\{env}\" ASSIGN accountBalance = "$52.65"
Dann erstellt er die folgende Aufforderung in einer Play-Aktion nach Snippet:
"{promptPath}YourAccountBalanceIs_{lang}.wav" "%{accountBalance}" "{promptPath}ToPayYourBillPress_{lang}.wav"
StudioAktionen, die Eingabeaufforderungen abspielen
In Studio können Sie mithilfe der folgenden Aktionen Aufforderungen verwenden:
-
-
 Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts.) ab. Bei Verwendung einer Datei wird die gesamte Datei abgespielt. Nur der Kontakt kann den Ton hören.
Ermöglicht den Benutzern die Eingabe von Ansagen als Text und die Verwendung einer computergenerierten Sprache für die Aussprache des Inhalts.) ab. Bei Verwendung einer Datei wird die gesamte Datei abgespielt. Nur der Kontakt kann den Ton hören. -
-
-
Auch die ASR-Aktionen wie Asrmenu ermöglichen es Ihnen, Aufforderungen einzuschließen.
Viele dieser Aktionen unterstützen den Sequenzeditor. Einige Aktionen, wie z. B. Reqagent, haben eine Sequence-Eigenschaft, sind aber nicht mit dem Sequenzeditor verbunden. Für diese Aktionen können Sie Ihrem Skript eine Play-Aktion hinzufügen, um auf den Sequenzeditor zuzugreifen. Sie können die Eingabeaufforderung in dieser Aktion erstellen und aus der Eigenschaft Sequence kopieren. Dann können Sie sie in die Sequence-Eigenschaft der anderen Aktion einfügen und die Play-Aktion aus Ihrem Skript löschen.
Audiodatei-Anforderungen
Audiodateien, die in Studio-Skripten als Aufforderungen verwendet werden, müssen unkomprimierte WAV-Dateien sein, die die folgenden Spezifikationen erfüllen.
- Bitrate: 64 kbit/s
- Abtastgröße: 8 Bit
- Kanäle: 1 (Mono)
- Abtastrate: 8 kHz
- Audioformat: CCITT μ-Law